Visual Overview
Project Gallery
Snapshots from development, testing, and deployment.






Next-Generation AI Smart Glasses
Bridging Closer via English Sign Language Recognition
Closer is an advanced wearable solution integrated into a sleek smart glasses form factor. Utilizing an ultra-compact compute core, the glasses capture hand gestures, process spatial landmarks via MediaPipe, and leverage edge intelligence to provide instantaneous English Sign Language translation. By translating signs into high-fidelity synthesized speech, Closer empowers the deaf and hard-of-hearing community with seamless, real-time social interaction.
Integrated camera and compute core designed for a lightweight glasses form factor, enabling mobility and hands-free use.
GestureNet: A proprietary deep learning architecture optimized for the nuances of Arabic sign semantics.
Recognized signs are spoken aloud instantly via the Windows Speech API with configurable audio delay.
End-to-end recognition latency under 300ms — from hand gesture to spoken word.
Closer is a two-way Closer bridge. Whether you communicate with sign language or speech, a single launcher puts both modes at your fingertips.
For deaf & mute users who communicate via sign language.
For hearing users speaking to a deaf/mute person.
The brilliant minds behind Closer
Project Member
Project Member
Project Member
Watch Closer recognize English sign language in real time.
Snapshots from development, testing, and deployment.
A concise technical breakdown for academic review.
Deaf and mute individuals face significant Closer barriers in everyday life. Existing solutions are either costly, require specialized hardware, or do not support two-way communication. Closer addresses this by providing an affordable, open-source English sign language recognition and speech-to-text system that runs on widely available hardware.
The solution utilizes a high-performance distributed architecture:
This offloaded computation model ensures the wearable remains lightweight and thermal-efficient while delivering server-grade AI performance.
| Property | Value |
|---|---|
| Architecture | Multi-Layer Perceptron (MLP) |
| Input | 63 normalized landmark values |
| Output | 20 classes (English sign vocabulary) |
| Training Samples | 40,000 (20k original + 20k mirrored) |
| Training Epochs | 100 |
| Confidence Threshold | 60% |
| Smoothing | Majority-vote window (n=2) |
Training data was collected using a webcam and MediaPipe for landmark extraction. Each of the 20 gesture classes was recorded with 1,000 samples. To make the model hand-agnostic (works with both left and right hands), the dataset was doubled via Mirror Augmentation: all X-coordinates were negated, mathematically mirroring every right-hand sample into a left-hand equivalent without any additional data collection.
Raw landmarks from MediaPipe are normalized before training and inference:
This ensures the model recognizes signs regardless of how far the hand is from the camera.
| Metric | Value |
|---|---|
| End-to-end latency | < 300ms |
| Signs supported | 20 English gestures |
| Hand support | Both left & right |
| Operating environment | Any indoor lighting |
| Network requirement | Local Wi-Fi only |
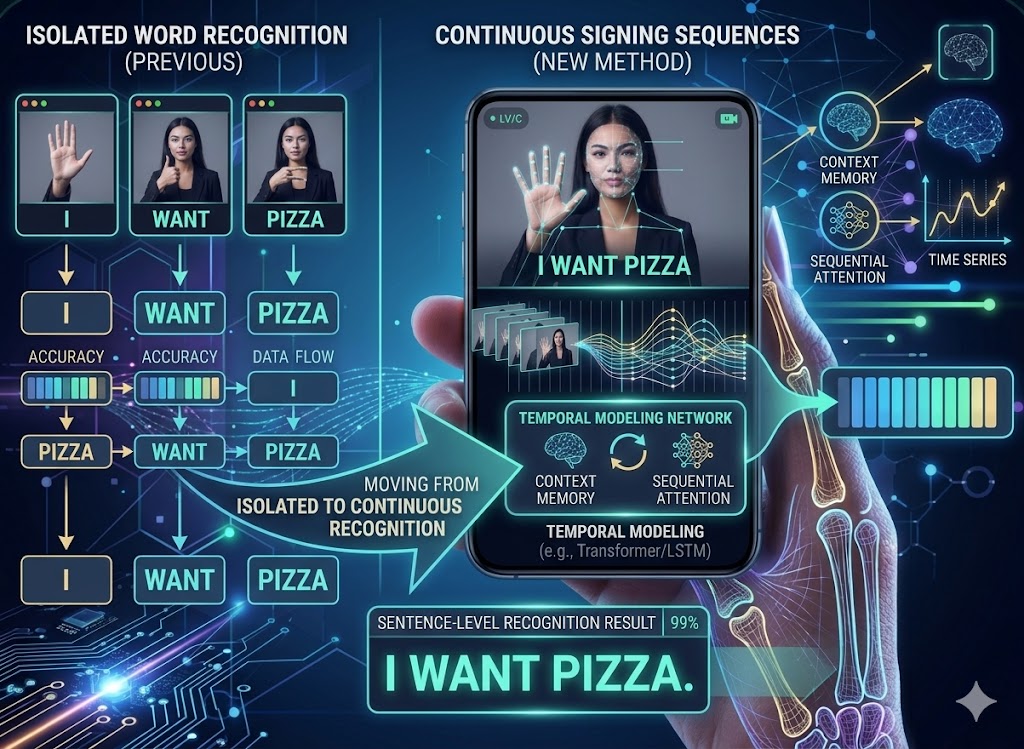
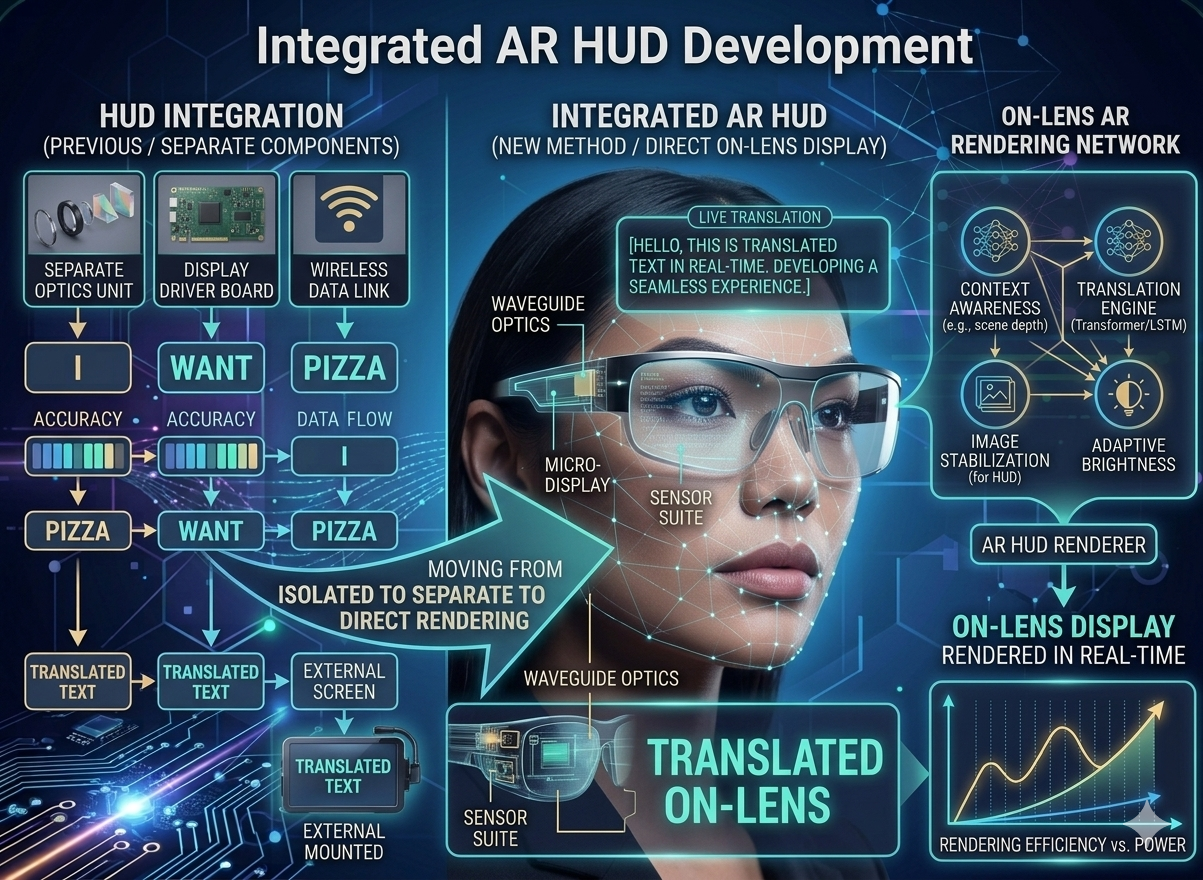
Planned improvements and future development directions.


For providing the resources, labs, and academic environment that made this project possible.
MediaPipe (Google), FastAPI, PyTorch, OpenCV, and all the open-source libraries that power this system.
Engineered for accessibility. Redefining human Closer. 💚
Global Innovation University · Faculty of Technology